Chapter 6 Creating datasets and replicability
Objectives:
- To use the scientific method for data analysis
- To generate research questions based on our observations
- To create data sets based on metrics of interest
- To open and use data sets in a computational environment
Today’s laboratory will be focused in the essentials of building data sets.
Data sets can be built with absolutely anything you can make an observation from and ask a question about.
Before we start, however, lets answer these questions:
Question 1
- What are the main steps of the scientific method?
- How do you define a research question?
- What is the difference between a research question and a hypothesis?
6.1 Creating basic datasets
So, we have a bag of candy in front of us.
Bags of candy have several different elements on it: The various flavors, the diversity in colors. Some may have different shapes, ect.
The objective for today is to ask research questions and create a dataset that allows you to answer different questions based on your research focus (in this case, your candy bag)
6.2 Asking biological questions and identifying measurable outcomes
- Create groups of two students
- Open the bag of candy and generate some observations about it. It can be about anything you find interesting or peaks your interest
Question 2
Create at least three observations from tour research object and add them here:
- Choose one observation and create a research question and a hypothesis for it
Question 3
-
Research Question:
-
Hypothesis
Using a physical notebook, have a list of variables you think would be directly measurable to test your hypothesis
Measure the variables and write down the results in the same physical notebook.
Question 4
Take a photo of the page of the notebook and add it here.
- Did your results answer your research question? How about your hypothesis?
Question 5
-
Research Question:
-
Hypothesis
6.3 Creating a clean raw dataset
Using the same dataset, organize your data in a simple data frame using Google Sheets or EtherCalc
Copy your spreadsheet into
atom, paste it and save it file into a folder in your desktop calledBIOL120with atxtextension (something likedata_sheet_candy.txt)
WARNING:
Do NOT save any of your files with a space or with weird characters (such as ?><,/’;:=+-).
If you need to use a space, use an underscore (_) or separate the names using camel case (i.e. Instead of data sheet candy.txt use either data_sheet_candy.txt or dataSheetCandy.txt)
In your
R studio, go to theSessionmenu in the toolbar, selectSet Working Directoryand select yourBIOL120folderRun the following code after changing the name of the .csv file into what you named it
my_data <- read.table('data_sheet_candy.txt', header = T)i.e. If my file is called
dataset.txt, then I change the code toread.table('dataset.txt')
Executable Code Chunks
Executable code chunks are sections in your R markdown that allow you to execute or run code inside your file! That means you can do a lot of cool stuff within those chunks, like read datasets, create tables, and plot figures.
Executable code chunks look like this:
```{coding language goes here}
code goes here
```
That means we can use bash, R and even python (as long as you have installed the correct packages) inside your R markdown document.
An example using bash to get the time:
```{bash}
date
```## Mon Nov 21 21:10:49 EST 2022
You can also use R as in here:
```{r}
(my_data <- read.table('data_sheet_candy.txt', header = T))
```## Flavor Number
## 1 Lime 12
## 2 Lemon 13
## 3 Banana 55
## 4 Strawberries 23- Check your file loaded by using the code
View(my_data)or also adding this into your notebook andknitingthe document:
my_data## Flavor Number
## 1 Lime 12
## 2 Lemon 13
## 3 Banana 55
## 4 Strawberries 23- In your R markdown notebook do the following:
Question 6
- Add the code to read and visualize the data frame
- What are the names of your columns?
- What do each of you columns represent?
- Write if your results are able to test your hypothesis and give an explanation why
6.4 Creating basic (basic) plots in R
Now that you have your data set readable by a computer program, we can do some very basic visualization to make it easier to interpret.
To do so, we need to install one simple R package that will allow us to create plots. This package is called ggplot.
R Packages
An R package are a collection of code, data, functions and other elements that allow you to extend the usage of R.
Some packages will help you plot, some others will allow you to read data into R in a better and faster way.
To use a package the first thing you have to do is Install it. After the package is installed, you just need to load it into the library.
Installing a package
For example, to install ggplot2, write the following code just once in the CONSOLE (aka. The window in the lower left corner of your R studio)
install.packages(‘ggplot2’)
Installing a package
If you check the console, you’ll see that the code will say
DONE: ggplot2
That means that your package has been installed.
Loading a package
Now, we need to load the package to get the functions to work.
To load the package, in your R markdown add this in code block
{r} library(ggplot2)
loading the ggplot library
The command library loads the package into your R environment, and now you can use any of its functions!
To learn more about packages in R, read the following link
Load the
ggplot2package (make sure you have installed it first)Make sure your data frame is still loaded into
R.
Question 7
- How would you check that the data frame is still loaded in R? Write the code and a justification
- Now, lets do a basic plot. Chances are that your data set has a set of columns with the colors/flavors/shapes in one column and the number of said elements in a second column.
If this is the case, you can create a simple bar plot. A bar plot summarizes all the information for each category (i.e. The element you are using to qualify the data into different sets) in the x-axis and creates bars in the y-axis where the height represents the number of data points for said category.
To create the plot, modify and execute the following code:
library(ggplot2)
ggplot(data=my_data, aes(x=Flavor, y=Number)) + geom_bar(stat='identity')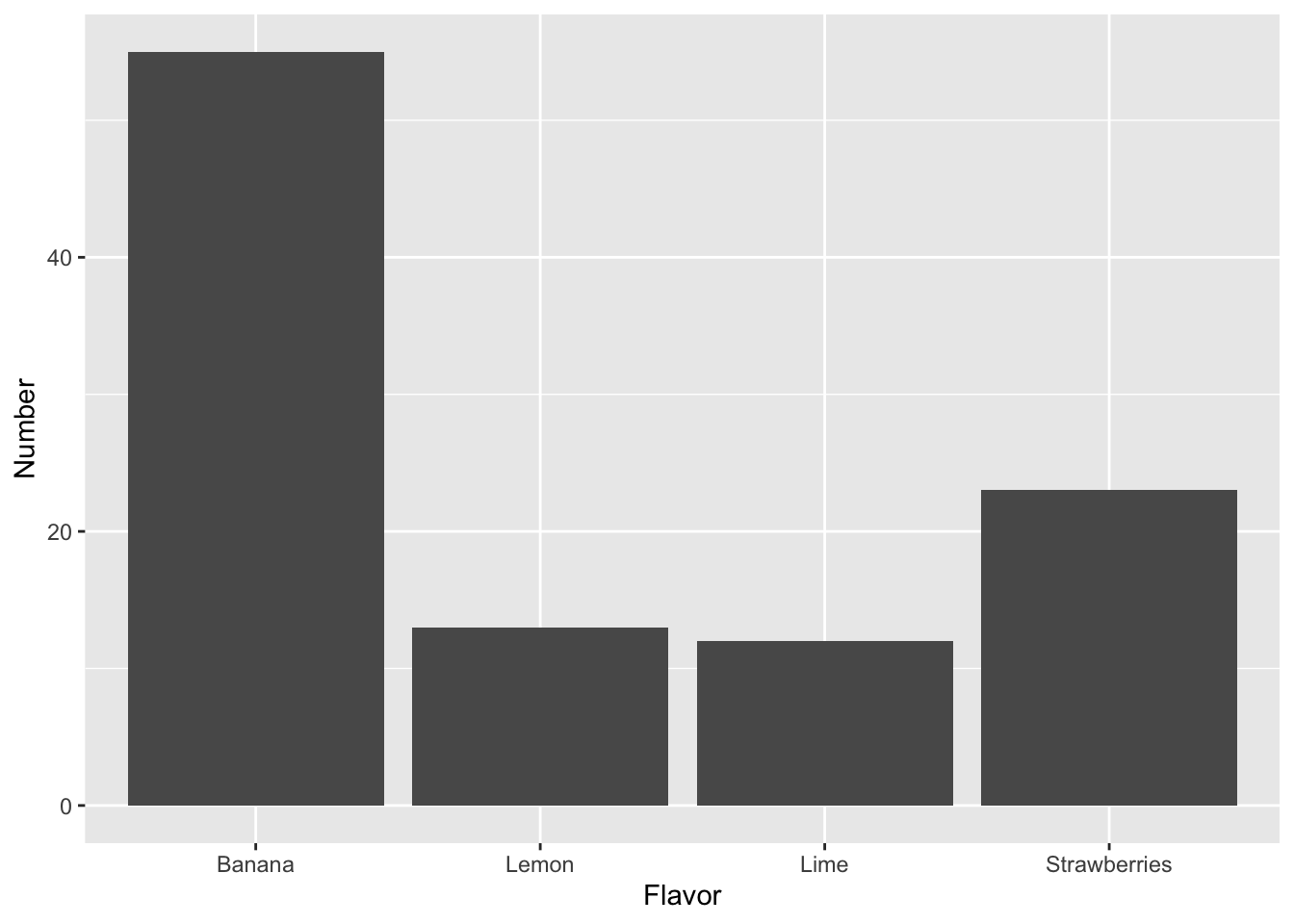
Question 8
- Is this an easier way of comparing your data? Explain why.
6.5 Comparisons between groups.
Now, lets see how our data collection is compared to the other groups
- Get together with another group
- Compare your two data collections and answer the following:
Question 9
- What was the question the other group asked?
- Did they data collection help them answer this question?
- Import their data set into your
Renvironment. That means to ask them for their original, hand written data sheet and re-digitize it usingGoogle SheetsorEtherCalc
Question 10
-
Load the data sheet into
Rand show it in your Markdown notebook - Compare it to their digital data sheet. Is it identical?
- Now, talk to the other group and start thinking of a way to measure the differences between the two data sets.
Asking questions
For example: One group has M&Ms and the other has Skittles. What are two features in common these two candies have? Color? Flavors?
You can, for example, measure the number of colors for both Skittles and M&M’s and compare them
Question 11
-
Research Question:
-
Hypothesis
- Create a digital data frame with these two comparison and add them to
R
Question 12
-
Load the data sheet into
Rand show it in your Markdown notebook
- Lets create a plot to compare the two different candies
Comparing data sets
When you want to compare between different sites/treatments/types of candies is important that the data frame has an extra column that tell you where these are from.
For example:
| Flavor | Number | Candy |
|---|---|---|
| Lime | 12 | Skittles |
| Lemon | 13 | Skittles |
| Banana | 55 | Skittles |
| Strawberries | 23 | Skittles |
| Lime | 5 | Starburst |
| Lemon | 0 | Starburst |
| Banana | 12 | Starburst |
| Strawberries | 3 | Starburst |
In this case, we can separate the flavors from each candy.
Modify the following code with your column names:
ggplot(data=two_candies, aes(x=Flavor, y=Number, fill=Candy)) +
geom_bar(stat='identity', position="dodge")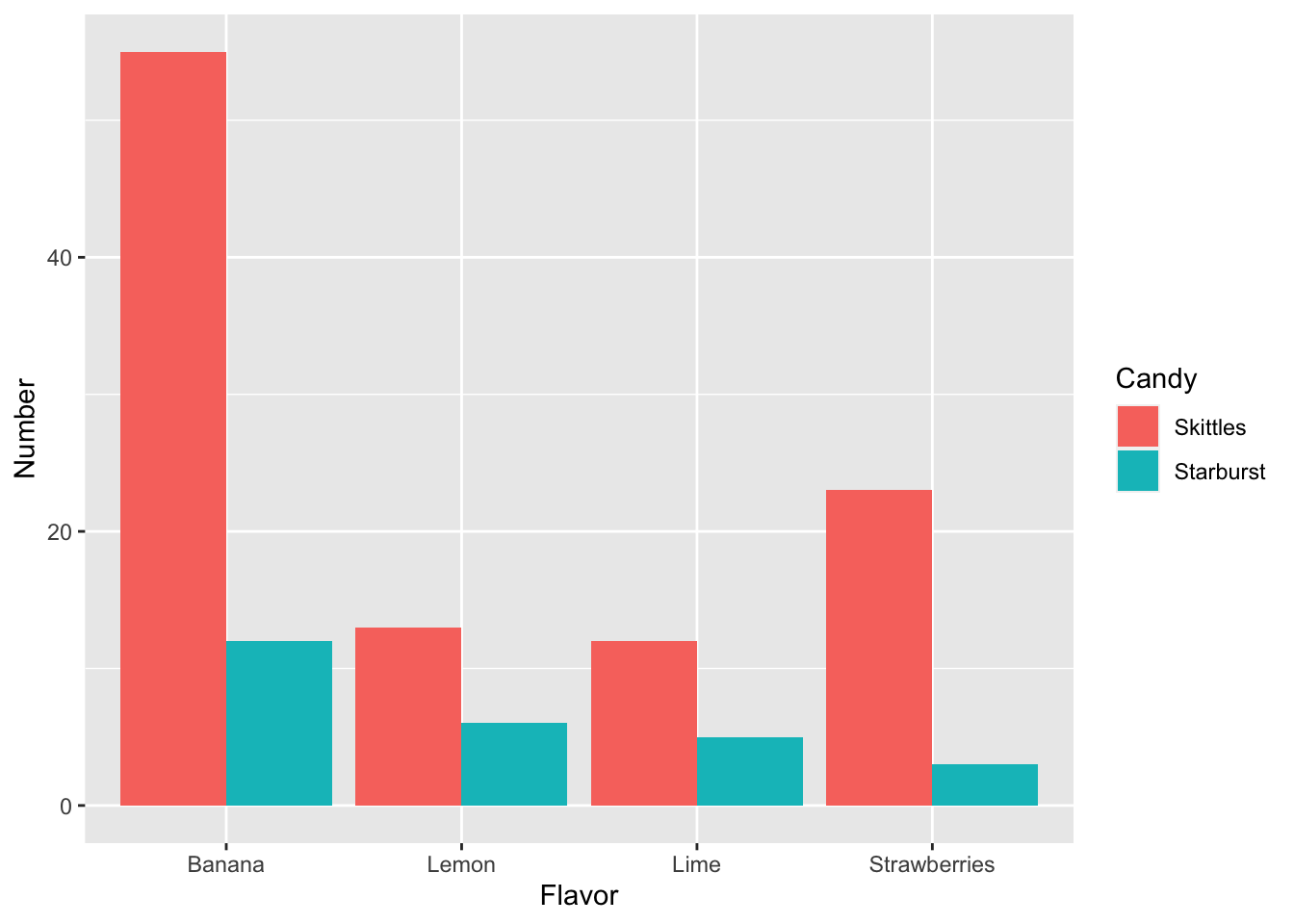
Question 13
- Can this graph help you answer your research question? How
- What do your results show, based on the research question?
-
Compare the code for plotting the
two_candiesdata set versus the code for themy_datadata set. What changed?